

Are You Getting the Most Out of Your Cloud Network?
Pushing the Limits in a Managed Environment

As users of managed Kubernetes clusters (such as AKS, EKS, or GKE), we often focus on deploying and managing our applications at a higher level, relying on the underlying infrastructure to handle the low-level details. However, there is a world of optimization opportunities beneath the surface, which sometimes is left to the mercy of default configurations. In this blog post, we'll embark on a journey to the depths of kernel tuning, shedding light on how adjusting kernel-level settings and understanding low-level concepts can significantly enhance the performance of your infrastructure.
One critical aspect of this optimization involves recognizing that transitioning to a more powerful VM or a specialized machine doesn’t automatically alter the kernel’s default settings. Though these defaults are generally optimized for smaller instances, they can limit the performance capabilities of larger nodes.

Although we are using Azure as an example, the concepts discussed here can be applied to most cloud providers.
Before we dive into the specifics of kernel tuning, it's important to note that we will be using Ubuntu as our example throughout this blog post. However, the concepts and techniques discussed here can be applied to other Linux distributions with similar kernel architectures.
Journey from network device to the application
Let's explore the optimization opportunities for the journey of a network packet from the NIC to a Linux process.
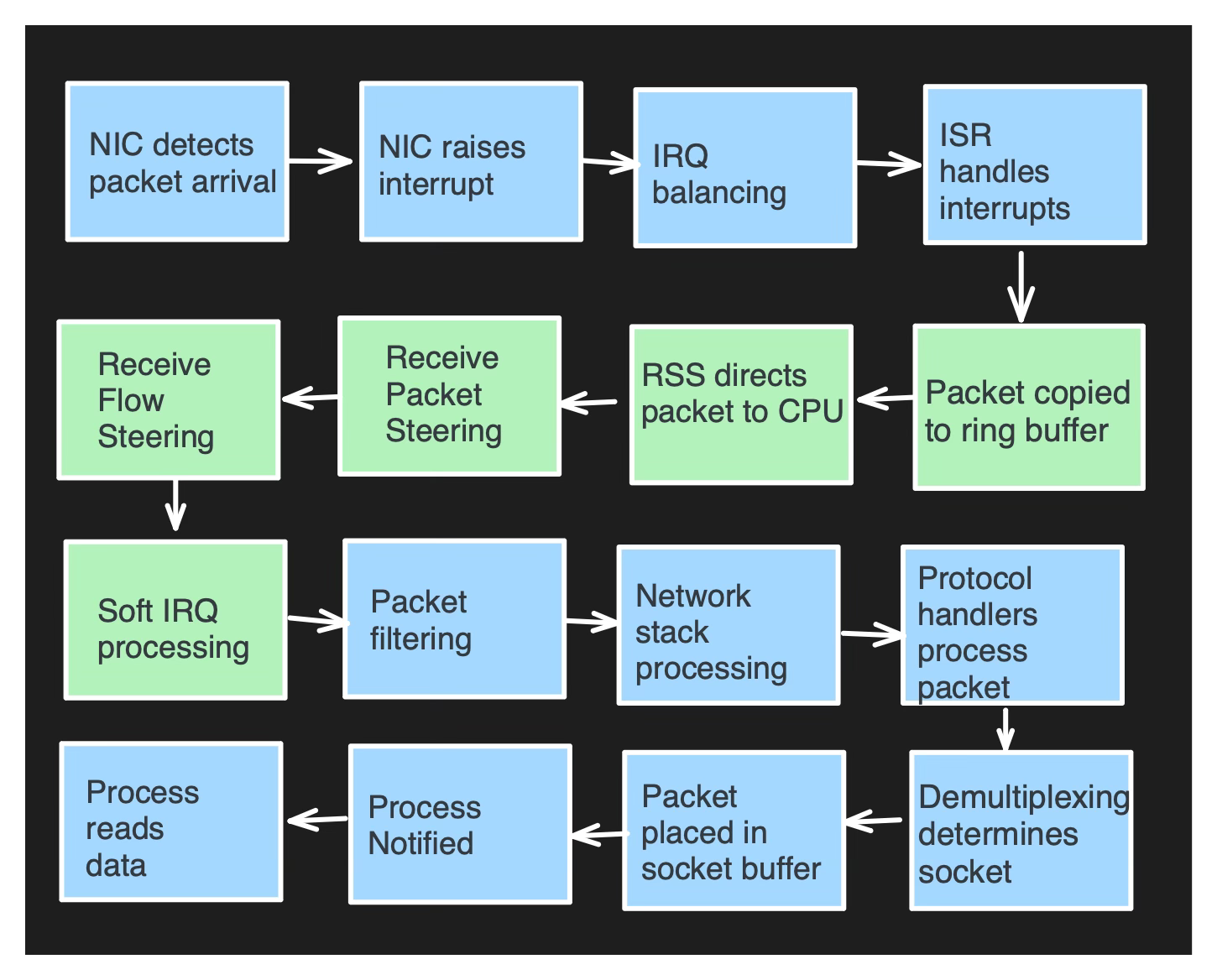
The green-highlighted steps in the flowchart illustrate the areas we will target.
Optimizing the Ring Buffer for High Network Traffic Spikes
When dealing with high network traffic spikes, one of the critical areas to focus on is the ring buffer. The ring buffer is a fixed-size buffer that temporarily holds incoming packets before they are processed by the kernel. If the buffer is too small, it can easily fill up during traffic surges, resulting in packet loss. By tuning the ring buffer size, we can mitigate this issue and improve network efficiency.
Let’s first check the defaults we have in our AKS cluster.

So we have a default of 1024 and maximum allowed values in our instance type is 8192
Which means depending on the nature of our network load we are not leveraging the maximum allowed values. In our case we were seeing a network device packet drop across nodes which had high network usage. Usually we just blamed it to high network usage.
After tuning the value to a higher value, we saw a dramatic change in packet drop.

Distributing Network Processing Load Across CPU Cores
In a high-performance environment, ensuring that network processing is efficiently distributed across multiple CPU cores is crucial. Without proper distribution, some CPU cores may become overutilized while others remain underutilized, leading to suboptimal performance and increased latency. Three key features that can help address this issue are Receive Side Scaling (RSS), Receive Packet Steering (RPS) and Receive Flow Steering (RFS)
Receive Side Scaling (RSS)
RSS works by distributing the network interrupt handling across multiple CPU cores. When a packet arrives, the NIC generates an interrupt that is handled by a specific CPU core, determined by the RSS hash.
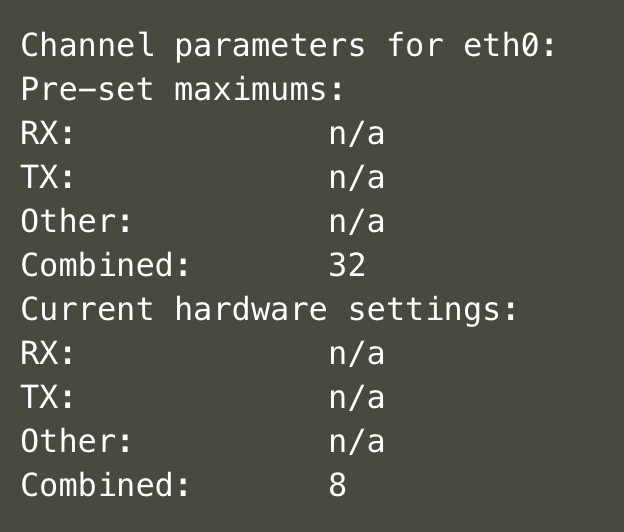
This means that the network traffic can be distributed across those 8 queues for both receiving and transmitting data. This results in each queue being mapped to one of the 8 cores.
We can verify this by checking the network indirection table

Our NIC hardware allows about 128 entries in the indirection table and all of those are mapped to 8 queues. But we are allowed to have as many queues as our VM cores, in this case 32.
ethtool -L eth0 combined 32Now we do have those 128 entries mapped to all 32 queues.
By increasing the number of RSS queues, we can achieve several benefits
Parallel Processing: With 32 queues, there are more parallel paths for processing incoming packets. This can lead to higher overall network throughput, especially beneficial for high-bandwidth applications.
Reduced Queue Depth: With more queues, the depth of each queue is reduced, leading to less time packets spend waiting in the queue, thus speeding up processing.
Faster Packet Processing: By distributing the workload more evenly across CPUs, each packet can be processed more quickly, reducing the overall latency.
Receive Packet Steering (RPS)
RPS is designed to distribute the processing of received packets across multiple CPUs, based on the hash of the packet flow. This can help to alleviate bottlenecks on a single CPU core.
It's important to note that RPS focuses specifically on the packet processing stage, where the actual handling and manipulation of packet data occur. This is separate from the interrupt handling phase, which deals with the initial reception and queuing of incoming packets by the network interface.
Systems with a high number of CPU cores can leverage RPS to utilise their full processing potential. With a low number of CPU cores the benefits are almost null in this case.
Most modern kernels do support RPS, you can quickly verify it in the boot configuration
grep RPS /boot/config-$(uname -r)
CONFIG_RPS=ylets check on any of the queues
cat /sys/class/net/eth0/queues/rx-0/rps_cpus
0The default value for the rps_cpus file is typically 0, indicating that no CPUs are explicitly assigned for RPS, and the packets are processed by the CPU handling the interrupt. But we can do enable it for our system.

This way we improve network performance by balancing the load of packet processing across all CPU cores, reducing the likelihood of any single core becoming a bottleneck.
By enabling RPS we achieve:
Enhanced Load Distribution: By distributing packet processing across multiple CPUs, RPS helps balance the workload, preventing any single CPU core from becoming a bottleneck. This ensures more efficient utilization of all available CPU resources.
Improved Throughput: With RPS enabled, multiple CPU cores can handle packet processing simultaneously, leading to higher overall network throughput. This is especially beneficial for systems with high network traffic.
Reduced Latency: By spreading the packet processing load across multiple CPUs, RPS reduces the time packets spend waiting in the queue, leading to faster processing and lower latency.
Receive Flow Steering (RFS)
Receive Flow Steering (RFS) is an enhancement to Receive Packet Steering (RPS) that aims to improve cache locality and performance by steering packets to the CPU that is already processing the relevant flow. This ensures that the CPU cache remains "hot" with relevant data, reducing latency and improving efficiency.
RFS maintains a flow table that maps each flow to a specific CPU. This table is populated as packets are processed.
When a packet arrives at the NIC and triggers a hardware interrupt. The interrupt handler or NIC driver performs minimal processing and schedules a soft IRQ for the packet.
A hash is computed based on the 5-tuple information of the packet (source IP, destination IP, source port, destination port, and protocol). This hash uniquely identifies the flow.
If the flow is found in the table, the corresponding CPU is determined. If not, a CPU is selected based on the current load or other policies, and the flow table is updated with this new entry.
The flow table provides the CPU ID that should process the packet. The packet is then enqueued for processing by the identified CPU.
The designated CPU processes the packet, handling the protocol stack (TCP/UDP, IP) and delivering the packet to the appropriate socket buffer in the user space.
The benefits of enabling RFS include:
Improved Cache Locality: By processing packets of the same flow on the same CPU, RFS improves cache hits, reducing memory access latency.
Reduced Context Switching: Minimizes the need to switch context between CPUs, leading to more efficient CPU utilization.
If you are using CPUsets in your application, you might even see greater benefits in performance and efficiency due to improved CPU resource allocation and enhanced cache locality.
SoftIRQs Processing
We just increased the ring buffer, optimized the RSS, enabled RPS and RFS to handle scenarios where packet bursts are common. But now you might seeing packet drop in certain situations where kernel cannot process packets quickly enough.

Increasing backlog can help in these situations to match the increased ring buffer. If the default value 1000 is not sufficient, you will require to do some iterations till you find the right value for it.
sysctl -w net.core.netdev_max_backlog=$new_valueSetting this value too high may not be ideal, as sometimes it’s better to drop packets. Because our VM's network specs are closely tied to the number of CPU cores, we decided to base the new value on a multiple of the core count.
Also we can choose to increase the budget, this will increase the packets we process in each soft IRQ invocation.
sysctl -w net.core.netdev_budget=$new_budget_valueYou can optimize your system for different scenarios, whether you need high throughput or low latency. Probably default values won’t cut for both extreme situations.
Automation @ Scale
We won’t go in details about how to set it up the automations but lets talk about the systems used to automate these issues we mentioned.

We are using Kubernetes and will leverage its tools to optimize our system management. We have two DaemonSets. The first DaemonSet runs our custom Go code to check if each node has the correct version of a systemD unit. If the systemD unit is not running, it labels the node; if it is running, it removes the label. The second DaemonSet runs only on nodes labeled by the first one, ensuring the systemD unit is installed and started if it's not already. Finally, the systemD unit itself will configure kernel settings based on the number of CPU cores.

Summary
In this blog post, we explored various kernel-level optimizations that can significantly enhance the performance of your infrastructure by focusing on network packet handling and processing. We discussed tuning the ring buffer, enabling RSS, RPS, and RFS, and adjusting SoftIRQs settings.
These optimizations can help mitigate packet loss, balance network processing loads, and improve overall efficiency. While this post covered several key areas, there are still other optimizations to consider, such as fine-tuning socket buffer settings and exploring more advanced kernel parameters. If you have any questions or would like to share your experiences, feel free to reach out to me directly.
Happy optimizing, and stay tuned for more deep dives into system performance enhancements!